In the early days of Mailgun I started working on a distributed lock service. Something I had worked on briefly at Rackspace. Even as I implemented the thing, I had the sneaky suspicion that it was a bad idea. So, let’s talk about why the locking service never took off at Mailgun…
The Synchronization problem
In both distributed and monolithic systems, you often MUST have things which are performed in an orderly or synchronized manner. In almost all cases where synchronization is required, it is due to the system needing to write something. Whether it’s a financial system recording the order of debits to credits, or an apache access log on a server. Write synchronization happens everywhere.
In monolithic design, you have an easy answer to this problem, just use a mutex lock. Indeed, most logging systems use a lock in order to ensure log lines do not clobber each other and remain legible. But a lock in a monolithic design has the same problem as a lock in a distributed design, they both create a synchronization point, which is typically bad for scaling horizontally.
Most of the time, we don’t see a problem with using a lock, as our laptops and services don’t span 8+ CPUs to do their work. However, in a very high concurrency system where there are a non-trivial number of CPUs in use, kernel locking — regardless of how fast — eventually gets in the way of scaling.
Consider https://github.com/gubernator-io/gubernator where you have a service which needs to handle tens of thousands of concurrent requests, each of which needs access to a central in-memory cache of rate limits. In such a situation, lock contention will eventually become a problem. To solve this problem, you have two options, you can shard or you can eliminate the lock.
Because Gubernator doesn’t do anything CPU intensive, each request simply needs access to the shared cache. The answer to the synchronization problem for Gubernator was to remove the need for a lock by using a S3-FIFO cache. We did attempt to shard, but the overhead of calculating the hash to shard with, and the increased number of queues and threads needed (thus increased context switching) made this an unviable solution for our use case.
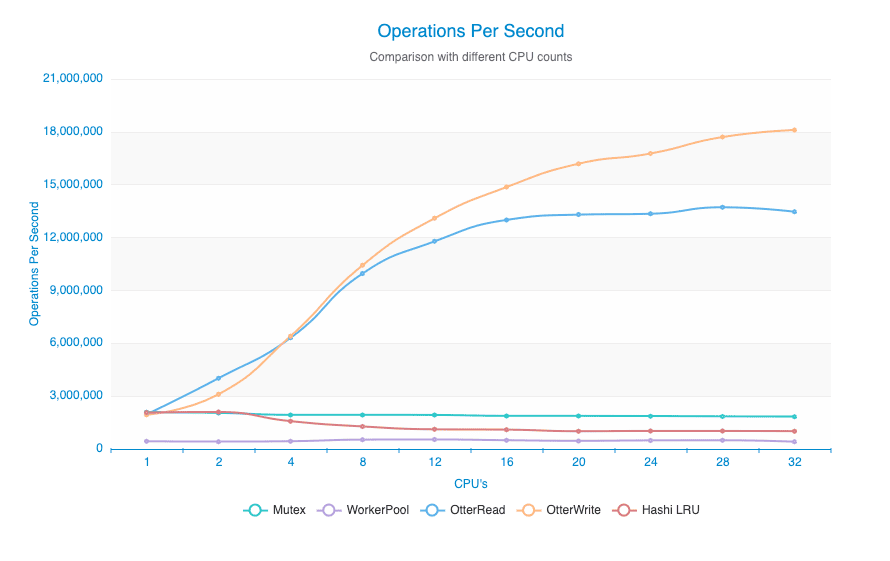
Looking at the graph below, you can see the Otter implementation (S3-FIFO) easily beat out the WorkerPool (Hash) implementation in our tests. Interestingly, we were only able to see such an improvement when running this test on a machine with a very high number of vCPUs. Running this test on my development laptop showed very little performance improvement over the WorkerPool or Mutex implementation. This is because the lock contention only showed up once we got to sufficient horizontal scale.
Digging Deeper
To get a deeper understanding of what is happening when you use a lock with multiple CPUs, consider a few traces I took while looking into Gubernator lock contention. We can visualize the effect lock contention has on our CPUs by using the trace tool built into golang.
In the trace below the tiny green vertical bars indicate CPU work (the time when the CPU is doing work), the opaque areas between the green lines indicate CPU wait (waiting around to do something). The graph below shows a trace I took of a benchmark running for a few seconds, then running the same benchmark test again, but each time increasing the number of CPUs golang can use by calling runtime.GOMAXPROCS(processors) in between each run, until we reached 32 processors. The benchmark’s only job is to do as much work as possible in as little time as possible. As such, an efficient use of resources will use as much CPU as possible without allowing the CPU to wait around for more work. Thus the most efficient implementation will show a solid green bar, the more green you see, the better.
Here is Gubernator’s mutex implementation
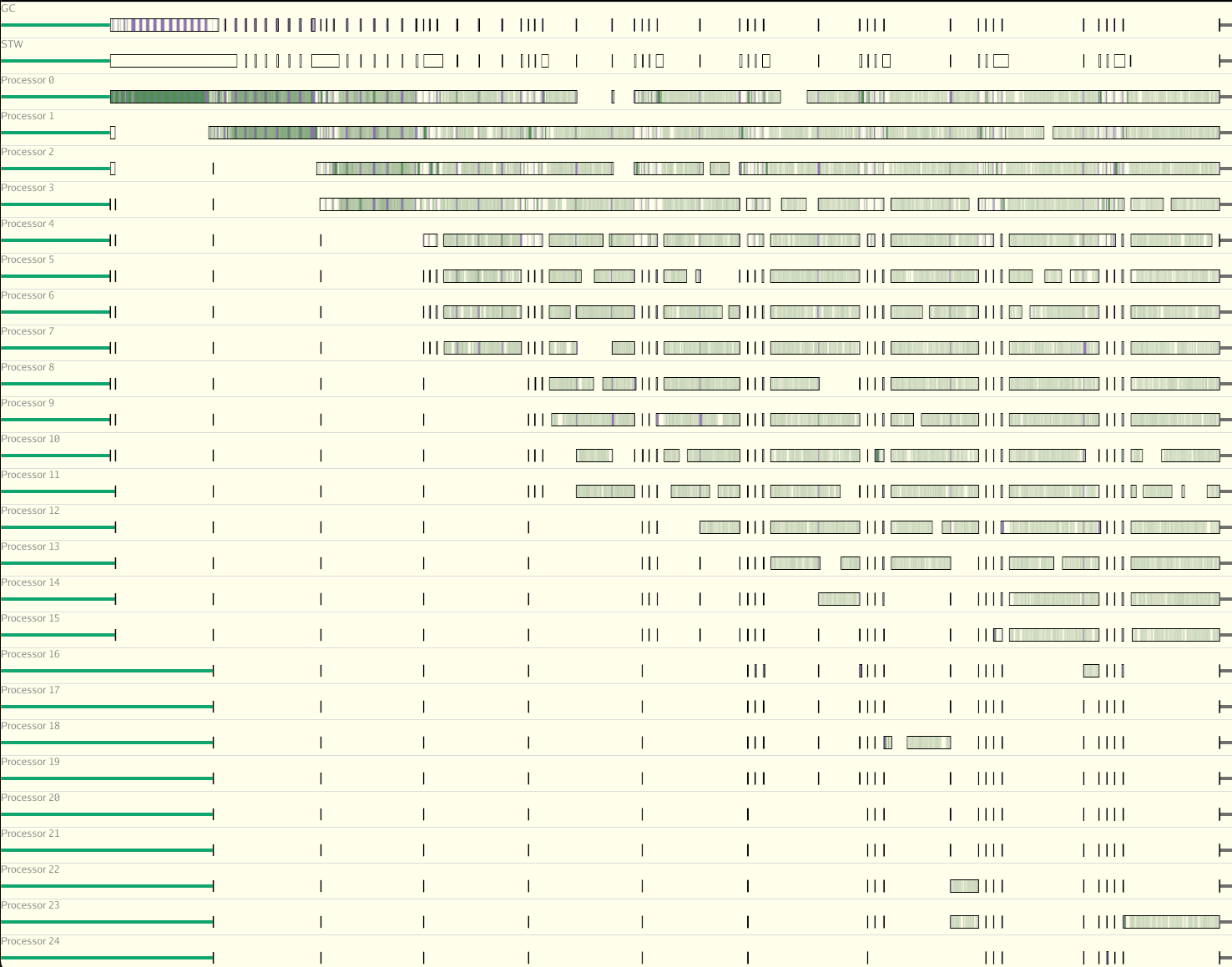
The first few seconds of the test use only 1 CPU, and you can see a mostly solid green line on processor 0, which indicates that the CPU was engaged for most of the time during that benchmark run — which is what we want. After that run, you see the test run again but with 2 CPUs in the test, and the green lines — though not as solid as before — are evenly distributed between the 2 processors. Next you see 4 processors engaged and again, very even distribution. After we get to 8 CPUs the distribution starts to fall off and even though we are using more CPUs the efficient use of each CPU starts to drop off dramatically, until we get to 32 processors where several CPUs mostly sit around waiting for lock access. This waiting around is all due to the mutex lock or synchronization that has to occur for all of the CPUs to access the shared cache. For the curious, golang implements a 2 mode mutex, once starvation occurs, you get what you see above.
Now let’s look at the same benchmark but this time, with no mutex, using a lock-less shared cache.
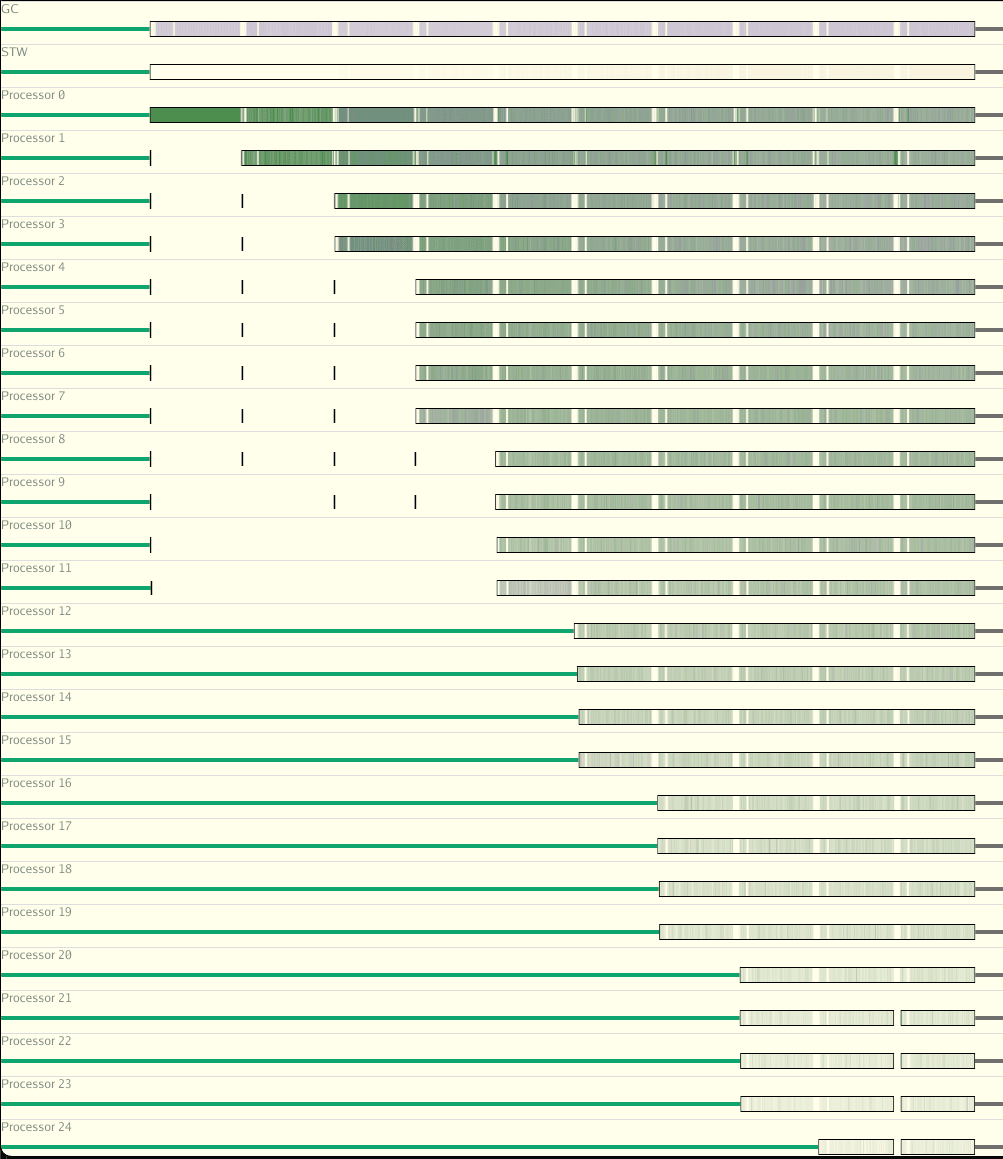 We can quickly see the distribution of work (the green lines) is more evenly distributed. Since we’ve avoided synchronization, we get more efficient use of the CPU resources at our disposal. We never get a completely even distribution of CPU due to the context switching that needs to occur between threads, but you get the idea.
We can quickly see the distribution of work (the green lines) is more evenly distributed. Since we’ve avoided synchronization, we get more efficient use of the CPU resources at our disposal. We never get a completely even distribution of CPU due to the context switching that needs to occur between threads, but you get the idea.
If the work we gave each thread was more CPU intensive, you would likely see an even distribution. For Gubernator, the work each thread is doing is literally a simple “Get this value from the cache, and return it”. As a result, context switching degrades our efficiency as the number of CPUs increases. And, now you know why a single threaded Redis server can be so fast 😉
The Locking Service
At the beginning of this article, I teased that I once worked on a distributed lock service at Mailgun. Now… Hopefully, you understand why this turned out to be a bad idea. Distributed locking sounds like a good idea on paper; but, just like a lock in a monolithic application, it’s not great for concurrent scaling, which is why you want to build a distributed system in the first place!
The lock service implementation wasn’t anything special, it was a single service instance which held on to a reservation which a client requested to gain the lock. If the client who gained the lock didn’t unlock it within the time it promised, then the lock would release, and allow some other client to gain the lock. The initial version was purely in memory with no storage at all. Thankfully, I worked with some very smart people and they convinced me it was a bad idea, and I abandoned the project after it very quickly became apparent that despite having written the service in this super fast, brand new language called golang, the service just wasn’t fast enough to handle the scale we threw at it.
What did we do instead? Well, I’ll answer like any good Principal Engineer should… “It depends…”
A few Solutions that have worked for us:
Spread the load across multiple tables
We have successfully implemented round robin writes/reads across many MongoDB collections. By writing & reading to many collections (tables) we spread synchronization across many CPUs and files. This works well in situations where rebalance of the data isn’t required, such as when used as a queue for ingestion. Rebalancing data in a sharded system can be an expensive operation and depending on the workload, is often more trouble than it’s worth. However, when used as a write queue from which the rest of the system can pull from — which is very similar to Kafka’s topics and partitions — you bypass any write synchronization issues your database may have, which allows you to ingest massive amounts of data which your system can then process as it sees fit. For the curious, we did use Kafka; just not for our ingest queue. I swear we had a very good reason for it! I guess I’ll have to write about that some day. If you want, you can read about The Write Synchronization Problem which I used when on-boarding new devs, to explain some of the concepts I’m describing here, so there is a bit of an overlap.
Consistent Hashing
There were some situations where we needed a synchronization point, but we wanted to avoid the rebalancing problem. The way to get the best of both worlds is to separate your sync point from your storage. We do this by using a consistent hash ring algorithm to determine which node in a distributed system should “own” the synchronization. Then, when a bit of work that requires synchronization happens — just like in a sharded solution — we hash a key for that work and send the work to the node the hash ring tells us “owns” that synchronization process. In this way, keys which hash to the same value — regardless of which node received the work — are always forwarded to the same node for processing.
This works great for “This can only happen once anywhere in the cluster” style things. The result of that synchronization work is often stored in an un-sharded database. This is because the important part — the synchronization — was performed in the service, not the database. This is great, since it’s easier and cheaper to scale up and down a service than it is to scale a database. See You don’t know how to Cloud
The TLDR is, most of the problems where you think you need a distributed lock, we solved by using a Consistent Hash or the Saga Pattern.
Reservation Queues
Reservation queues were at the heart of a lot of what we did at Mailgun, so I want to quickly touch on this topic, as the reservation pattern is a very close cousin to a lock. The nice thing about the Reservation Pattern in Queues is that much like a lock, you gain exclusive access to an item for a period of time. Unlike a shared mutex lock, you are not locking a shared resource in order to create a synchronization point. The Reservation only says that a part of your distributed system has gained exclusive access to process a bit of data, no one else can process it except the entity which owns the lock on that item. This particular locking pattern scales, as you are not gaining the exclusive right to a shared resource, but instead to process one of many thousands or millions of items which could be processed in parallel.
Avoid synchronization
Much like the lock free implementation in Gubernator we talked about earlier, you may THINK you need a lock, but often, if you look closely, you find that you actually don’t need a lock. We have found that if you avoid thinking about your system like you would a relational database, by that I mean, avoid thinking in terms of data consistency, and embrace eventual consistency, embrace data normalization via single table design, and design data models which lend to concurrent processing, then most of the situations where you thought you needed a lock, go away.
The Saga Pattern
This discussion is close enough to transactions that I had to put this in here. When we needed to do distributed transactional things, we used the Saga Pattern and this worked really well for us. See Reservation Pattern in Queues
The Database as a synchronization point
Databases are very good at synchronization, for they must synchronize many threads attempting to write to a single table. But as we’ve seen above, synchronization will eventually impede our ability to scale. So… the simple answer to avoid sync contention in a database, is to shard across more than one table, database or cluster.
At Mailgun we needed a way to quickly enqueue messages to be sent. In order to do this, we spread message writes across multiple databases and collections with MongoDB to great success. As a result we were able to scale MongoDB to many billions of messages a day with a few clusters of 3 nodes running on general compute. By writing to hundreds of collections (tables) per node we were able to avoid lock contention and get the most out of the resources we had.
With replica sets, when MongoDB writes to a collection on the primary, MongoDB also writes to the primary’s oplog, which is a special collection in the local database. Therefore, MongoDB must lock both the collection’s database and the local database.
Use With Caution
Since synchronization is literally built into the database, it’s very tempting to use the Database and the transactions they provide as the synchronization point for EVERYTHING. I would advise caution here, because the database is an expensive part of, and often is THE MOST EXPENSIVE part of, your infrastructure. It’s better suited for storing bits on disk, than for synchronizing all of the things for you. If you rely on the DB for synchronization, you will inevitably need to shard and rebalance your database in order to continue scaling, and BTW, you are scaling the most expensive part of your infra.
As an example, one of our email competitors — which we later acquired — built their entire tech stack around PostgreSQL. As a result, they used PostgreSQL for ALL their synchronization. In order to scale, they built their own custom sharding solution which, unfortunately, sharded by customer, and it was a nightmare. In order to maintain relational consistency, during a rebalance they had to move all a customer’s data together in a single operation. This isn’t a problem if the data is small, however, if they on-boarded a customer that grew too quickly, with terabytes of data for a single customer, they had no hope of ever rebalancing them to a different cluster as the operation to move all that data would take hours, during which the customer would not be able to send or use their system. Their only recourse was to upgrade to beefy, very expensive database clusters when rebalancing was not an option.
Mailgun was able to scale efficiently by avoiding exactly that problem, by not using the database as a synchronization point. Instead, we intentionally created synchronization points in our code. This allowed us to scale up and down independent of the database as the load increased or decreased, thus saving us lots and lots of money.
The End
I’ve run out of things to talk about here, but I will eventually talk more about the saga pattern and distributed transactions, as I’m currently working on Querator which takes all of the lessons learned from implementing the Saga pattern and in code synchronization into a friendly and reusable service.