Rejection of the cloud has been a popular topic as of late. This sentiment is only amplified by reports of cloud customers receiving seemingly inexplicable or exorbitantly expensive invoices from their cloud providers.
The prevailing narrative appears to be that the promise of cloud was somehow a mistake. That we all got suckered in by the “cloud Kool-Aid,” and those who aren’t embracing on-premises server racks are either intoxicated or delusional with cloud fever.
However, based on my experience, I would argue that the majority of cloud users simply don’t know how to properly leverage cloud computing. In essence,
Most people just don’t know how to cloud!
I helped build and scale Mailgun.com which was known for having a very high profit to cost ratio. That ratio resulted in us being profitable very early in the journey. I didn’t completely appreciate how rare this was, until we acquired a competitor of ours who was struggling to operate efficiently. As someone who has seen both efficient and inefficient cloud usage, I have a few choice words to say about how people should cloud.
Always have an SLI & Monitor it
When it comes to ANY Software-as-a-Service (SaaS) cloud products that automatically scale, one should never develop on such a platform without first calculating or estimating expected usage, and then using that estimate to define a Service Level Indicator (SLI) which you then monitor for costs overruns and alert you when they exceed your estimated bounds.
Those estimated costs should be up on your dashboard. They are not nice to have, they are a requirement!
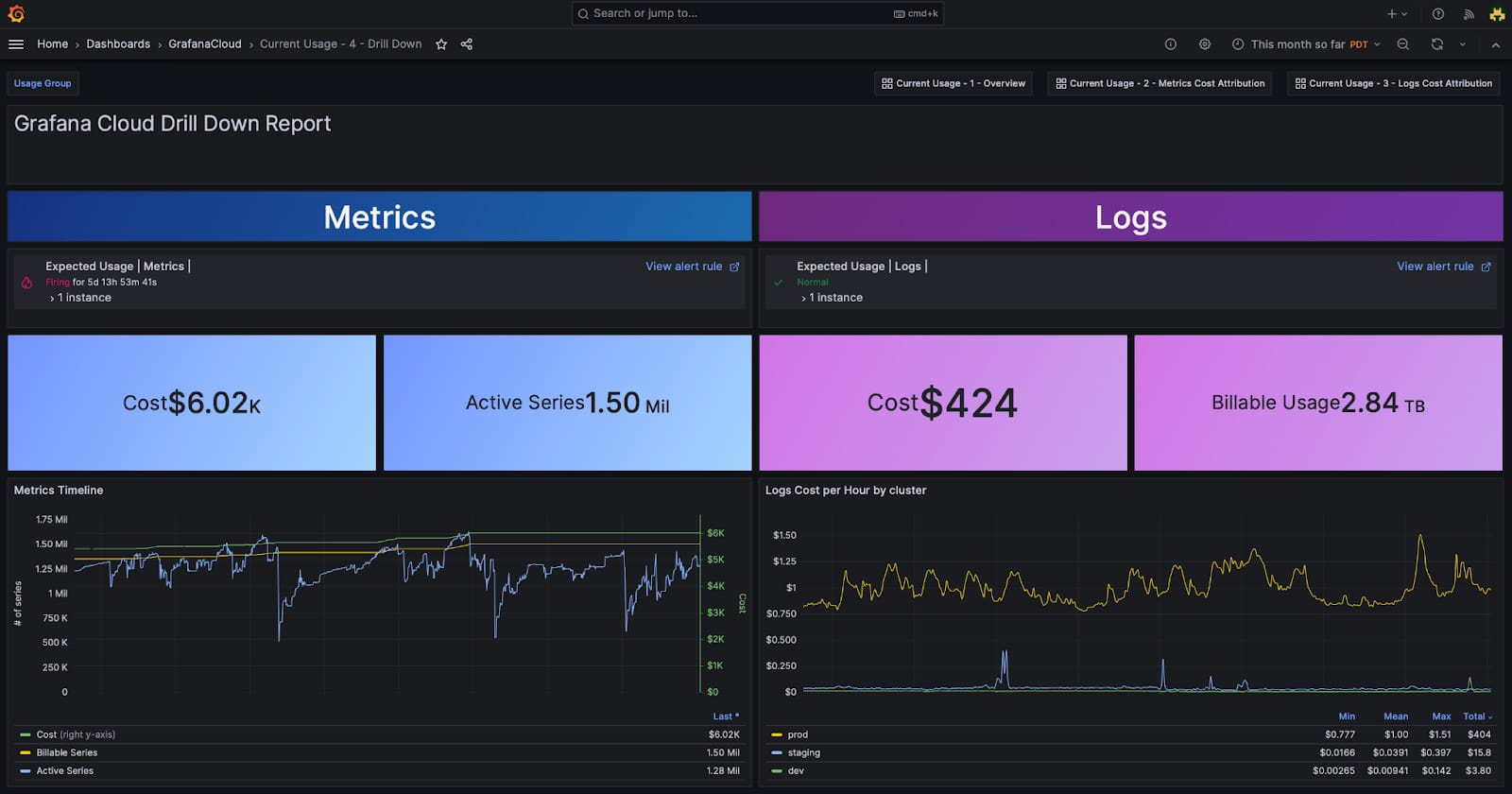
Screen shot from Metrics Cost Management in Grafana Cloud
This is not as hard as it sounds, estimating lambda costs, network ingress and egress costs and essentially, anything that has an uncapped charge associated with it should be step one of any design. Once you have that estimate in hand, use it to establish an SLI for the thing you are building and then monitor those for breaches.
GCP makes this relatively easy to do.
- Defining SLIs https://youtu.be/uhpAScSerec?si=eSaGlP_DRxDGlygn
- Creating Budgets https://youtu.be/F4omjjMZ54k?si=bvqjsyQiligDshpj
For an overview on compute estimation, I highly recommend this excellent repo and accompanying talk by Simon Eskildsen
https://github.com/sirupsen/napkin-math
Design for the cloud
You MUST design your software for the cloud, forget any dreams of taking your existing product and moving it to the cloud and expecting magical cost savings. We’ve acquired companies that have tried to do this and it doesn’t work.
Cloud Native also means your software is designed to run on general purpose Compute. If your workloads require vertically expensive servers to run, forget it, you are likely better off running on prem with a one-time, super expensive hardware purchase. Everything has to scale horizontally across cheap general purpose Compute, including your Databases.
Databases
Vanilla PostgreSQL and MySQL should be avoided — Note I said “Vanilla”.
You REALLY want a clustering capable Database which is designed to spread the load across many low-cost general purpose Compute and Disks. Traditional RDBMS are designed for highly optimized vertical scaling, typically in a Active-Passive HA configuration. This often results in big expensive servers multiplied by 3, (1 primary and 2 secondaries) as you scale. If you absolutely need an RDBMS (most people actually don’t) then use something that provides Active-Active HA, built-in Clustering and Sharding.
You REALLY want to separate your Compute and Storage workloads. This means you should avoid doing CPU intensive things on the Database. Instead, preform CPU based computational things in your app. Once the computation is done, you store the result on the DB in the form it will be retrieved. This allows you to scale your CPU bound processes quickly (because you don’t need any attached disk) which allows you to scale up during peak, and scale down during off peak.
Compute is more expensive than even the most expensive cloud disks. If your application is mostly craftings queries and waiting around for the database to compute a result, then your app is just a thin client for the database. Such designs are impossible to scale up or down on demand. Separating Compute and Storage saves you money and allows you to apply capacity management to compute and store separately.
There are PostgreSQL extensions that provide much needed features on this front, and for MySQL; there is Vitess.
Takeaways
If you can’t or don’t want to commit to any of these things, then the cloud is not going to be as kind to your wallet as was promised.
The power of the cloud is in low cost general purpose hardware that can be quickly spun up and spun down as needed. If your software is not designed to maximize this advantage then the promise of the cloud can never truly be realized.
For SaaS offerings like AWS Lambda, Aurora Serverless, etc., if your usage doesn’t have significant downtime (off-peak hours), you’re not going to see cost savings. If your app is running near 60% of capacity 24/7, you’ll almost always get more bang for your buck by self-hosting the database or application on a Compute instance under your control instead of a fully managed service.
I can’t stress this enough! The only way you’re going to see significant savings in the cloud is if you are scaling back during off peak. CPU’s are expensive, shut them down as quickly as possible.
This is the way; all others should invest in some server racks.